我喜欢 Rust 已经很久了,它的优点很明显,同时缺点也很明显。内存 Safe 无需 GC、零成本抽象、并发安全、几乎现阶段最好的工具链和配套外围建设、超强的覆盖面(上到 Web 云服务器,下到单片机),还有错误处理设计非常好。缺点嘛,学习陡峭?难以理解 Ownship,Borrow 之类的模型约束;写起来很慢?
长久以来,我们都认为这是 Rust 的缺点,但是实际上前两者都是可以通过锻炼思维和认知来解决的,而编译速度慢却一直拖慢着我的工作流,这一切在早几年似乎很好,AI 席卷而来之前我可有的就是耐心,常常一个算法一个功能写到凌晨,可,现在呢?我很难说我没有变,我开始变得一点都没有耐心了,一点都不想思考 Rust 代码怎么写,一点都等不了 Cargo 那个漫长的进度条,尤其是 ld 部分还没有进度,每次就干卡着,这真的很难受。
这一起难道就没有办法嘛?其实是有的,在大约一个月前,我尝试了一些办法让我的 Rust 开发流程更快,包括工作流优化之类的但是其实每次等的时间都卡在 Cargo 上,如果不能解决这个就不治本,那正好借这个机会来稍微说一下关于 Rust 开发中 Cargo.toml 配置调优相关的内容和配套外围配置吧。
后端理论
Rust 设计中,LLVM 其实有点偷懒,但也选的很好,不像 Go 一样自己维护 To 机器码的过程让 LLVM 大生态来做成熟的优化其实很好。整个 Rust 的编译流程大致可以说是源码跑一边词法分析、语法分析生成 AST,再经过宏展开、HIR 降级拍平!然后进入常规类型检查、亿点点借用检查,最终生成 MIR 了到这里为止,都是 Rust 编译器自己的前端在干活。而 MIR 之后的事情,就交给了 LLVM,比如把 MIR 翻译成 LLVM IR,然后 LLVM 跑一遍它那套优化 pass(从 O0 ~ O3 不等),最后生成目标平台的机器码,再交给链接器拼成 BIN 可执行文件。
那么到底问题出在哪呢,答案其实已经很简单了,LLVM 是一个很重的基础设施,重在生产环境下是对的,编译时间换执行时间是很好的哲学,它桥接了上层 Rust,还有 C、C++、Swift 等一大堆语言。这意味着它的优化管线是为"生成最优机器码"设计的,而不是为"快速完成编译"设计的。那几十个优化 pass 在 release 模式下跑一遍是非常很耗时的,即便是 debug 模式下的 O0,LLVM 依然要走完 IR 生成和机器码生成的全流程,而这个流程本身就不轻量。再加上 Rust 的泛型单态化会在编译期展开大量代码,交给 LLVM 的 IR 体量远比你源码看起来的要大得多,LLVM 要处理的工作量自然也随之膨胀。
Cranelift
所以本质上,编译慢的很大一部分时间不是花在 Rust 自己的前端而是花在了 LLVM 这个"重型后端"上。那么问题来了,有没有可能丢掉它嘛,答案是有的喵,有一个叫做 Cranelift 的后端就是一个为了这个需求做的。它最早是 Cretonne,2016 年启动,由 Bytecode Alliance 开发,最初是为 Wasmtime 包的饺子,才设计的代码生成后端;后被 Rust 官方收编作为可选的 codegen 后端。


那所以 Cranelift 到底应该快在哪呢,最好的阶段就是开发时期,这个时候也许你根本不需要接近完美的、极限优化执行效率的机器码,也许我们只需要一个快速的反馈而已,只要这个不是那么好的机器码和 LLVM 正经算出来的机器码语意等价就行了,早期的 Cranelift 其实做不到,因为有很多 Edge Case,虽然现在还是有,但是已经改善了很多了,现在出现 Cranelift 可以跑但是 LLVM 坏掉的概率差不多和你写 rust 触发 rustc ICE 差不多了。LLVM 为了生成极致优化的机器码,会跑几十个优化 pass,比如循环展开、向量化、常量传播、消除死代码之类的…… 很多很多,一层一层磨,而 Cranelift 的设计哲学完全不同,它大幅削减了这些优化步骤,只做最基本的寄存器分配和指令选择,用一趟线性扫描就完成代码生成,不反复迭代。同时它的 IR 设计也更轻量,是专门为快速从上层 IR 翻译到机器码设计的,不像 LLVM IR 那样承载着几十年的通用化包袱。
那么好处说完了,代价呢?首先显而易见的是 Cranelift 生成的代码运行时性能比 LLVM 差,根据场景不同大概会慢 10%~30%。但想开了其实就会发现,这在开发阶段根本不重要,我要那么快干嘛,你是跑分还是 CI release 啊,我就 tm 要跑 cargo build 快点,看看逻辑出没出来,而且我打赌,你写的大部分程序不可能 80% 以上的时间占满计算资源,肯定是要有业务来的,你开发的时候业务能有多大?cpu 怕不是全程都在摸鱼呢,反倒是我要看效果、验证逻辑。那编译时间换运行时效率,这笔账在开发循环里是不是应该倒过来算嘛。
代码生成单元
另外说说 codegen-units,这其实这就是一个控制编译器把 crate 拆成多少个最小单元给后端并行处理的参数,默认情况下,debug 模式是 256 个,release 模式是 16 个。数字越大,并行度越高,编译越快——因为可以同时利用多个 CPU 核心来跑后端代码生成。但代价是优化效果变差,因为每个单元是独立优化的,LLVM(or Cranelift)看到的上下文变小了,跨单元的内联和优化机会就少了。
但是在真实的 Release 下,一般来说都应该使用 codegen-units = 1 这样另一个极端的参数,只有这样才能让产物得到最大化的优化,毕竟你都用 Rust 了,编译时间换运行时性能难道不是理所当然的嘛。
优化等级
还有一个进程被忽略但是可以调的配置就是 opt-level,默认情况下应该是 "3",而作为 Release,更常见的做法是开到 "z", 这就是在不修改代码的前提下,可以获得的免费产物体积优化,为什么不开呢;但是呢,开发模式下这里应该配置为 "0",完全不优化才能获得最快的速度。
另外还有一个小技巧就是 Cargo.toml 其实可以给依赖和自己的代码设置不同的优化等级:
[profile.dev.package."*"]
opt-level = 3这样就可以给第三方依赖用 O3 编译,这样只会增加第一次冷编译的时间,后续就是增量编译的。外部依赖一般不会频繁更新,这里用 O3 自己业务代码用 O0 可以获得一般情况下权衡速度和体积的良好 dev 模式体验,但是 Release 模式下我还是建议 O3 或者 Z 拉满没啥好说的。
链接段优化
LTO(Link-Time Optimization)是另外一个很吃内存和编译性能的东西,而且这是大部分项目 Release 时候都推荐开的,正常编译时,每个 crate 是独立优化的,编译后端看不到 crate 之间的调用关系,某些跨 crate 的内联和死代码消除做不到,而这种情况的占比非常多;LTO 就是把这个边界打破,让优化器在链接时拿到所有 crate 的 IR,做一次全局优化。但是千万不要无脑 profile 上直接挂 lto = true 这样会让你的 Rust 编译慢到怀疑人生,好好检查一下使用 release profile 的时候挂上就行了。
干掉调试符号
和其他东西一样 Rust 的 debuginfo 和 symbols 就是存在于这里的,release 模式开启 strip 可减少非常可观的体积(通常是50MB vs 5MB)这样的逆天区别,除掉 symbols 也更加安全,毕竟大部分时候前端 source code 都是从 map 里面不小心 push 上 npm 泄漏的 :(
所以 dev profile 下没什么好说的,你总不能 strip 掉 debuginfo 吧,那样你就没法用 gdb / lldb 正常调试了,backtrace 里也看不到有意义的函数名。但是注意,ArchLinux 打包的时候会默认帮助你 strip,但是这里就会和我们有一点小摩擦,那就是我们已经 strip 掉了,后面可能会报错。这个如果写 AUR 的时候可以注意一下显式跳过这一步。
放弃 panic!
在正常的业务中,panic 应该是不能存在的,正常业务代码 runtime 遇到错误的时候,但凡是设计了容错的 Err 都应该被安全的返回,而不是暴力 panic 掉,就和 React ErrorBoundary 一样,应该被正常当作错误处理,panic 只有在代码坚信进入了不可能的状态,且无法挽回的时候才应该触发。我个人的哲学是放弃 panic,为什么呢?因为实际上业务代码可以作为 3层测试,第一层 happy path,第二层错误路径(无限种可能中的某一种),第三层才是 fuzz or 碰撞测试穷举出来的 Edge Case。工程学上来说,正确路径可以做到 100% 测试,错误路径可以一类 n 种变体中取 1种;碰撞测试纯粹是时间问题,大部分时候不值得,等你用户体量真的上来了,要做的时候你自己就会知道,通常我一律不做。
那么对于好的代码来说,就应该覆盖 1类正确路径的测试 和 至少一种错误路径的测试,而这一类的错误路径只要覆盖一个就可以测试被 Err 返回的情况,就可以写 fallback 逻辑,就自然的可以 thiserror 枚举 or anyhow 拦截拍平打印记录。总之就是你的代码会迫使你写出处理这些情况的机制,如果做到了这一层的话,panic 对你来说就没用了,可以理解为"理论上不可能",但是仅仅也是理论上,实际世界里面还有 OS 错误,内存错误,宇宙射线单电子 bit 反转,奇奇怪怪的溢出... 你永远不可能覆盖满这种情况,那为什么不要 panic 呢,那是因为这些情况其实都大概率,90% 的概率不是你的代码问题,panic 的本质就是发生时,Rust 会沿着调用栈一层层往回走,逐个调用每一帧里的析构函数(drop),清理资源。这个过程需要编译器生成额外的 unwind 表,就是给你找出你业务逻辑错误的地方,如果错误本身都大概率不是你的,这个信息有什么价值,存在还会增加编译产物的体积,也会给链接器增加工作量,关掉才是正解;你的代码测试到位了,足够自信建议配置 panic = abort。
实际测试
那么多说无益,实际来看看这一些组合下来的提升吧,这里拿一个我前几个月做的小玩具项目做为参考
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Language Files Lines Code Comments Blanks
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
CSS 5 152 113 16 23
Go 77 14556 12409 584 1563
JavaScript 23 2506 1999 232 275
JSON 93 1780 1780 0 0
Just 1 408 275 71 62
Makefile 1 15 8 3 4
Shell 16 1440 1075 166 199
SVG 1 9 9 0 0
TOML 20 502 419 3 80
TSX 75 3257 2718 132 407
TypeScript 390 36643 30350 1627 4666
─────────────────────────────────────────────────────────────────────────────────
HTML 2 41 32 7 2
|- CSS 1 37 37 0 0
(Total) 78 69 7 2
─────────────────────────────────────────────────────────────────────────────────
Markdown 95 5344 0 3578 1766
|- BASH 3 8 8 0 0
|- Go 2 21 21 0 0
|- HTML 1 25 15 10 0
|- JSON 6 317 317 0 0
|- Rust 1 10 9 0 1
|- TSX 1 11 9 0 2
(Total) 5736 379 3588 1769
─────────────────────────────────────────────────────────────────────────────────
Rust 181 31654 26951 1032 3671
|- Markdown 86 581 0 564 17
(Total) 32235 26951 1596 3688
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Total 980 99317 78554 8025 12738
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━这个项目里面 Rust 的部分差不多有 32K SCoL Rust,不包含依赖体积。
这个仓库实际上是一个有很多子项目的 monorepo,但是其中可以找出2个典型的例子,首先看看 Skeleton 这个包特点就很明显,代码量大,依赖极少,这个包会是整个项目里面 codegen 占比最高的,这个就会很适合 Cranelift 发挥,另外就是这个包也很干净,干净指的是纯 Safe Rust。
反观下面这个 CLI 包就不怎么合适,依赖多倒不是什么问题,理论上这样更能体现效率,但是这里有一个经典的二选一,可以在左上角看到 ring 这个依赖标记为可选了;那是因为项目本来用的是 aws-lc-rs,这两玩意都是 Rust 中的加密算法 Backend;但是为什么要可选呢,那是因为 ring 是纯 Rust 写的,而另外一个是 Asm 汇编 FFI 进来的,专为 x86 arm64 等主流 cpu 架构汇编加速,但是败也在这里,因为 Cranelift 的魔法只局限于纯 Rust,一旦你引入 Unsafe Code,or FFI C、ASM 之类的,此时实际上 Cranelift 兼容性极差。
但是这个也不是无解,其实可以用 cfg 选后端,Cranelift 模式下给 ring 来编译就好了。在按照上述描述配置好 dev 和 release profile 后,就可以简单跑一下 CLI 的编译对比,在这个情况下,开发至少比发布快 3倍,这还都是冷编译,没有增量的情况下;并且使用 O0 和关闭 LTO,dev profile 在后续的增量更新中都应该比 release 快几十倍不止。因为 LTO 之类的魔法实际上是通过拍平各个 crate 的边界得来的,那么都变成一个整体后,修改一处代码,当前一起都要重新编译不能被正确增量更新。
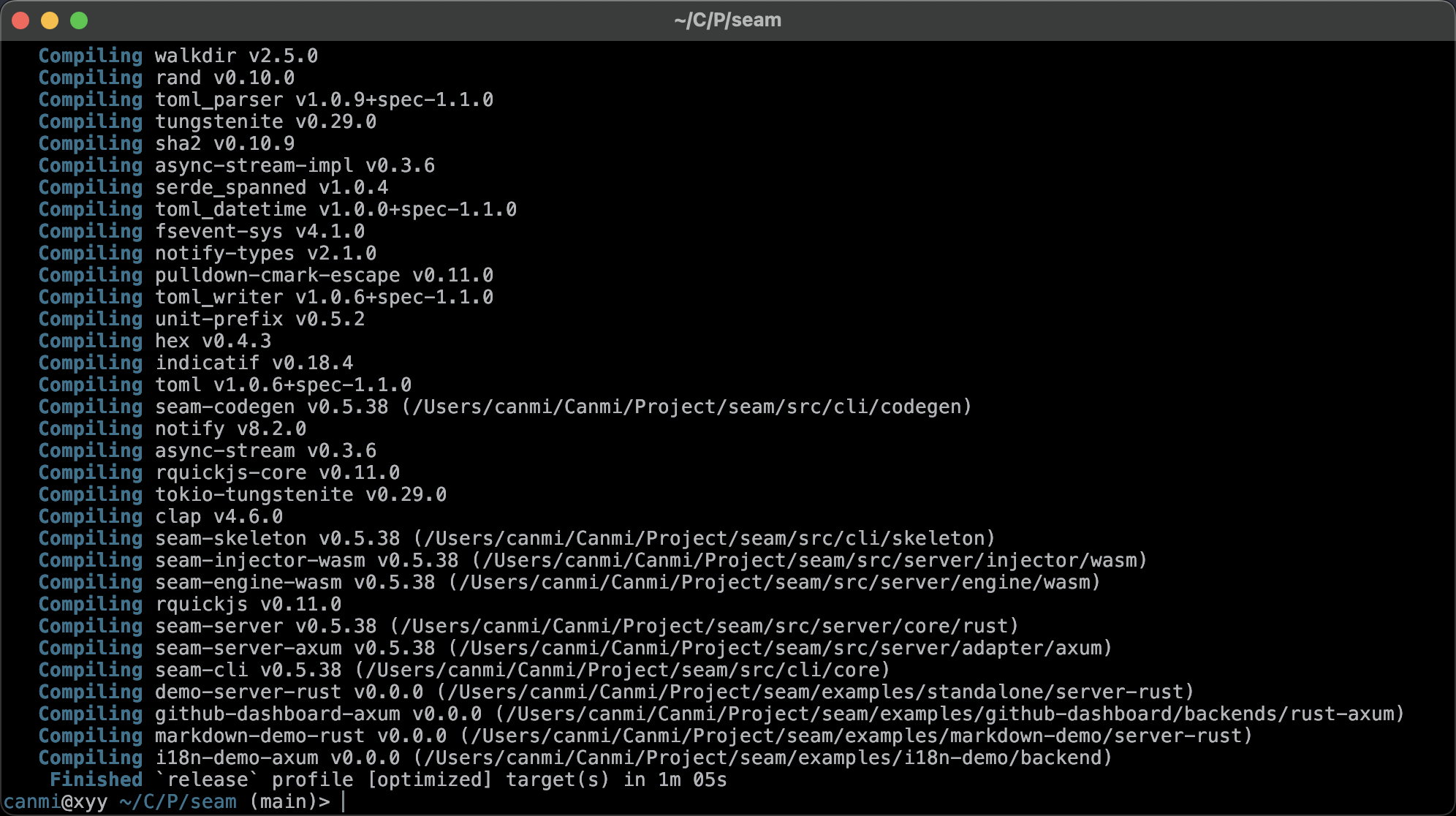
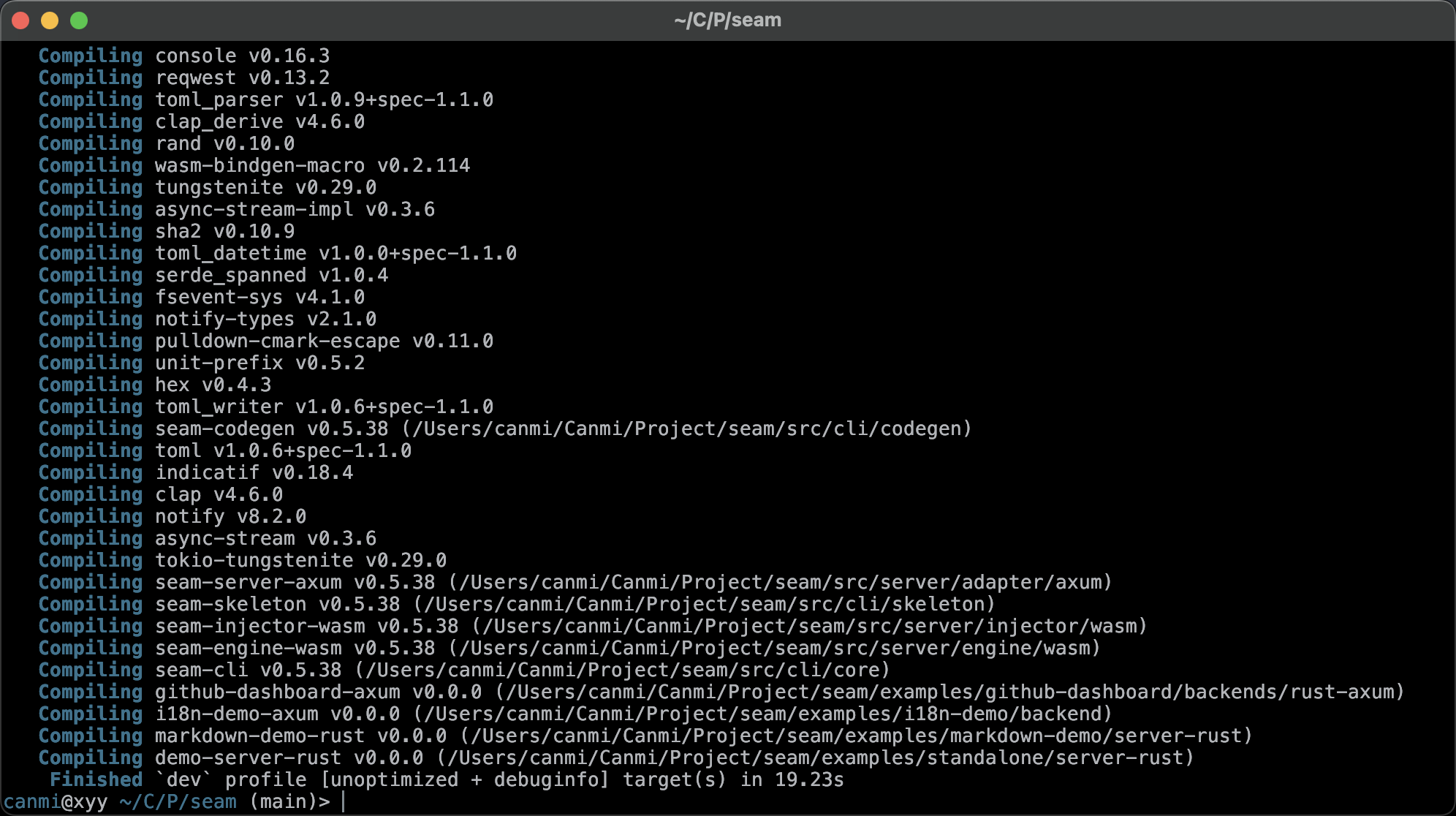
综合结果看下来这两玩意其实差不不大,谈不上质变但是绝对能明显感知,主要原因是 Apple Silicon 太猛了,M 系列芯片的单核性能、内存带宽都强的离谱,编译这种重计算+重 I/O 的任务刚好吃到这些优势。如果用 Linux 跑跑通常来说差距会更大,但是如果一台 macbook 刷 Asahi Linux 之类的肯定是 Linux 赢。
老旧的链接器
在 Linux 上,Rust 默认用的是 GNU ld(bfd),对,就是那个最老最慢的那个。单线程并且处理符号解析和重定位都是串行扫描,项目一大就明显拖后腿了,Linux 上可以试试 @Rui Ueyama 写的 mold 配置起来很简单.cargo/config.toml 里面加一行的事情。
[target.x86_64-unknown-linux-gnu]
linker = "clang"
rustflags = ["-C", "link-arg=-fuse-ld=mold"]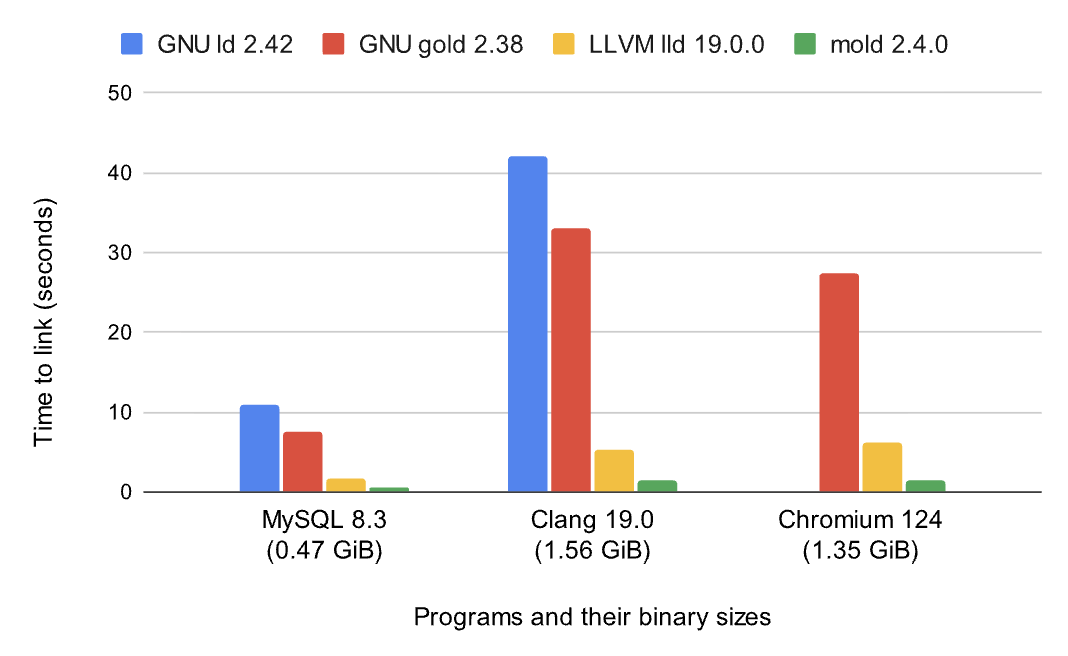
提升还是很明显的,但是很遗憾 macOS 上只有 sold 这个商业项目,但是好消息是 macOS 上的 lld or Apple 自带的 ld64 本身已经不慢了,尤其是 Xcode 15 之后那个新链接器,速度提升超级明显,不过这个玩意唯一的不好就是 macOS 无人值守 CI 和更新后每次都要 sudo Accept 一个条款,导致我好几次 CI 定时任务挂掉。
MUSL
我本人是一个 MUSL 厨,非常讨厌 GNU glibc,但是开发我还是推荐你使用 x86_64-unknown-linux-gnu 为什么呢,因为快,MUSL 最大的卖点是能生成完全静态链接的二进制——不依赖系统上的任何动态库,编译出来的东西拷到任何 Linux 机器上就能跑,特别适合容器和嵌入式,但是慢也慢在静态链接,因为链接器需要把所有东西都打包进去,链接阶段的工作量比动态链接大不少。
不过好消息是如果你用 macOS 的话,那就完全不用担心了,aarch64-apple-darwin 就是目前唯一的选择了,macOS 从设计上就不支持完全静态链接从编译速度的角度来说,这反而是好事。所以 dev profile 在 linux 上 gnulibc,macOS 上 libSystem,release profile 在 macOS 和 linux 上都可以 musl,因为 macOS 默认选择 linker 和 ar 的问题,唯一值得注意的就是可能需要配置一下 .cargo/config.toml
[target.x86_64-unknown-linux-musl]
linker = "x86_64-linux-musl-gcc"
ar = "x86_64-linux-musl-ar"顺便就是 zig 千万不要用,nightly rust 上的 zbuild 目前问题很大,需要交叉编译的时候,host 是 linux x86 推荐 cross 那个配 docker 来编译的就很好,环境全齐,如果你喜欢 glibc 这个也很好用,因为 glibc 只能向后兼容一般的参考都是 debian 发行大版本 -2 的 debian 上 glibc 的版本来编译,否则太新的 glibc 会让一大堆机器跑不动,这里并不是因为用了新 feature,而就是单纯判断一个字符串的版本就来气你。host 是 mac 请使用 rustup 原生 target + cargo build --release
UPX 是个坏东西
还有一个值得讨论的点就是关于 UPX 的使用;我知道我说我喜欢 musl,但是又追求小体积实际上很冲突,听起来没道理...
ooooo ooo ooooooooo. ooooooo ooooo
`888' `8' `888 `Y88. `8888 d8'
888 8 888 .d88' Y888..8P
888 8 888ooo88P' `8888'
888 8 888 .8PY888.
`88. .8' 888 d8' `888b
`YbodP' o888o o888o o88888o
The Ultimate Packer for eXecutables
Copyright (c) 1996-2026 Markus Oberhumer, Laszlo Molnar & John Reiser
https://upx.github.io但是实际上 upx 的存在让这个问题得到了解决,UPX 的原理实际上是把你的 BIN 压缩后包上一个解压 stub,运行时先在内存里解压再执行,这样就可以把二进制体积压缩到原来的 30%~50% 左右这样体积优势就会非常明显,但也正是因为这样,UPX + GNU glibc 动态链接就会有大问题,因为 glibc 动态链接的二进制里有一些特殊的 section 和动态加载机制,UPX 压缩之后可能会破坏这些结构,导致运行时找不到动态库 segment fault;但是反观 musl,这个就非常适合 UPX,本来就是全静态,内部稳定,UPX 后解压和压缩都很干净。所以 musl 的 release CI 其实可以多加一步 UPX 是非常加分的。
另外就是 UPX 也不能滥用,UPX 只适合长任务 or 低频任务,长任务是因为 UPX 启动的时候需要内存解压一次,这个过程虽然是全自动的但是需要一点冷启动时间,这个影响很少,但是在高频路径上还是很致命。所以长任务启动一次后台挂就很适合这个,但是我并不推荐无脑给 docker 镜像这种长服务的包塞 UPX,因为实际上这是内存换磁盘空间的行为,属于血亏,而且容器 Layer 的压缩实际和 UPX 是一样的,减少了分发的时候下载体积。反而推荐的环境是某些 CLI 的用途;节省超多磁盘空间并且启动解压时间几乎无感,而且 musl 天然也适合做 CLI,不然我就要点名批评 AUR 助手了,go 写的那个玩意但是没有静态链,导致我曾经遇到过 ArchLinux 上 yay 坏掉了,找不到动态库,本身又是系统管理器,无解只能另外 LiveISO 启动最后 chroot 救砖。
总结
最后这些好用的配置虽然可以帮助你快速区分 dev 和 release profile,在项目代码上来后只会越来越明显,但是我还是建议你多写一个 CI 来跑 Rust Stable LLVM Build,最好再加上你的各种测试一起跑,这样本地 nightly 的 rust 也不用切换了,Edge Case 也坑不到你,push 上去有问题就被 CI 拦了,这样就是目前最舒服的 DX 模式了;那这次就说到这里了,下次有空再摸吧